传统方法 History
error signals “flowing backwards in time” tend to either blow up or vanish。
bp算法中为什么会产生梯度消失? | 知乎
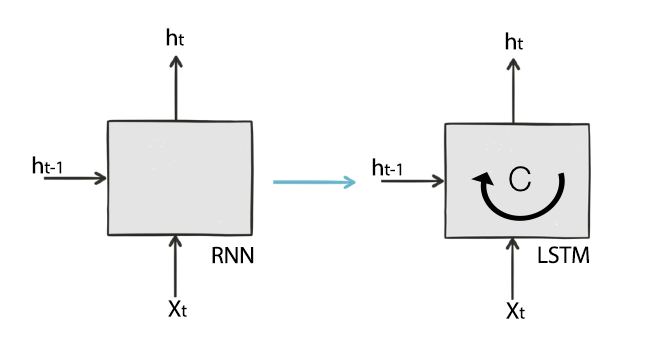
LSTM
LSTM网络是RNN的一种,专门设计用于解决long-term dependency/memory问题,1997年由 Hochreiter & Schmidhuber提出。
由于独特的设计结构,LSTM适合于处理和预测时间序列中间隔和延迟非常长的重要事件。
名字:long short-term memory
意思是vanilla RNN是short-term memory,sequence太长,
- LSTM只能避免RNN的梯度消失(
gradient vanishing); - 梯度膨胀(
gradient explosion)不是个严重的问题,一般靠裁剪后的优化算法即可解决,比如gradient clipping(如果梯度的范数大于某个给定值,将梯度同比收缩)。下面简单说说LSTM如何避免梯度消失. - 梯度弥散是什么鬼?
cell: memory_cell
关于梯度消失问题
梯度消失问题–直观解释
传统RNN中存在的梯度消失。
梯度消失 – 产生的原因
本质原因就是因为矩阵高次幂导致的
在多层网络中,影响梯度大小的因素主要有两个:权重和激活函数的偏导。
深层的梯度是多个激活函数偏导乘积的形式来计算,如果这些激活函数的偏导比较小(小于1)或者为0,那么梯度随时间很容易vanishing;相反,如果这些激活函数的偏导比较大(大于1),那么梯度很有可能就会exploding。因而,梯度的计算和更新非常困难。
https://www.zhihu.com/question/34878706
参考:
- BP Through Time and Vanishing Gradients
- Chapter 4: LSTM | Supervised Sequence Labelling with Recurrent Neural Networks
- 关于valve的比喻
梯度消失问题 – 解决方案
见后续的gate
梯度消失问题 – LSTM是如何避免的
1、当gate是关闭的,那么就会阻止对当前信息的改变,这样以前的依赖信息就会被学到。2、当gate是打开的时候,并不是完全替换之前的信息,而是在之前信息和现在信息之间做加权平均。所以,无论网络的深度有多深,输入序列有多长,只要gate是打开的,网络都会记住这些信息。
上面这个例子中,数据从实心1向后传递。通过gate的配合,成功在节点4和6输出该数据。数据流(梯度)不会因long-term传输而消失,有效解决RNN的梯度消失问题。即梯度保持
用数学来表达,就是f=1,i=0,那么就状态保持(完整)。f=0,i=1就状态遗忘(后面也LSTM的变种,采用i=1-f)。
- 当gate是关闭的,那么就会阻止对当前信息的改变,这样以前的依赖信息就会被学到。
- 当gate是打开的时候,并不是完全替换之前的信息,而是在之前信息和现在信息之间做加权平均。所以,无论网络的深度有多深,输入序列有多长,只要gate是打开的,网络都会记住这些信息。
参考
- LSTM | Sepp Hochreiter 1997
LSTM的设计思想
LSTM的核心:cell + gate。
用于解决传统RNN中的梯度消失问题 (Gradient Vanish)
关于gate
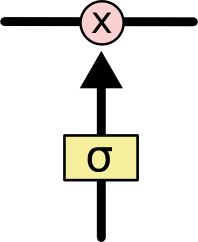 |  |
gate,即阀门、开关。取值范围[0,1],0表示关闭,1表示通行
使用一个合适激活函数,它的梯度在一个合理的范围。LSTM使用gate function,有选择的让一部分信息通过。gate是由一个sigmoid单元和一个逐点乘积操作组成,sigmoid单元输出1或0,用来判断通过还是阻止,然后训练这些gate的组合。所以,当gate是打开的(梯度接近于1),梯度就不会vanish。并且sigmoid不超过1,那么梯度也不会explode。
$") |  |
- RNN中时序传递采用tanh,是非线性变换,多次叠加梯度计算需要利用链式法则,难收敛。
- LSTM中 时序传递采用乘加操作,是线性变换,多次叠加可合并,梯度仍然容易求。链式法则求梯度,也会有f的乘积啊
Gates are a way to optionally let information through.
待看
- An Empirical Exploration of Recurrent Network Architectures.
- Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling.
关于cell的设计
$h_t$在RNN中承担两个角色:
- 作为当前时刻的
output,用于prediction - 作为当前时刻的
hidden state,用于时序信息的传递
LSTM将这两个角色拆分为 $h_t$和$C$,这样LSTM中的隐状态实际上就是$C$了,$h_t$作为output。通过这样的设计,输出层只利用$h_t$的信息,而不直接利用内部cell的值 $C$。
x和h_t-1做一个拼接,过sigmoide得到forget-gate。
forget-gate作用在c_t-1上。
为什么要设计cell?这样抽象的意义?
LSTM中c和h的区别: 仅仅是一个输出门的区别(c没过输出门,$h_{t-1}$作为上一时刻的输出,要过输出门)。
- c与x拼接送入forget gate呢?
- forget作用在h上呢?
https://zhuanlan.zhihu.com/p/28919765
为什么i不是是只作用于x,为什么还要作用于 $h_{t-1}$
GRU中合并了cell state和和hidden state
关于激活函数
sigmoid
sigmoid之类的大量用在rnn的门也并非是概率解释的问题。而是理想门函数是阶跃函数,但其本身不可导,所以soft成sigmoid是一种折中。而且rnn中sigmoid陷入饱和区本身也是一件无所谓的事儿,因为门的作用本身就是通过与不通过,他希望的就是激活值大量集中在0/1附近而不是其他的连续值。
为什么rnn中sigmoid陷入饱和区本身也是一件无所谓的事儿?不影响梯度消失?
tanh
为什么用tanh不用ReLU?
在CNN等结构中将原先的sigmoid、tanh换成ReLU可以取得比较好的效果。
为什么在RNN中,将tanh换成ReLU不能取得类似的效果?
从信号处理的方式说,要保证系统稳定。类似线性系统极点要在单位圆里,非线性直接加个激活卡住。所以简而言之:Relu不行,越界了;sigmoid差一半平面;只有tanh刚好。tanh还有个好处是零点梯度为1,这个性质比sigmoid好,relu在右半平面也是1,但越界不稳定,然并卵了。
参考:https://www.zhihu.com/question/61265076/answer/239987704
接口设计
1 | output, (h_n, c_n) = lstm(input, (h_0, c_0)) # pytorch的接口 |
LSTM可以看做有两个隐状态h和c,对应的隐层就是一个Tuple。
这里可以对比RNN的接口。
在RNN中 $output = c_t = h_t$,即$h$既是hidden state又是output
为什么lstm代码里和有些图里,习惯吧output称作h(hidden)? 前面已经解释了
这里为什么要用 tuple 呢?直接把它们拼成一个 Tensor 不行吗,tuple 还得一个一个遍历,这多麻烦?
不行。因为多层 RNN 并不需要每一层都一样大,例如有可能最底层维度比较高,隐层单元数较大,越往上则隐层维度越小。这样一来,每一层的状态维度都不一样,没法 concat 成一个 Tensor 啊!);而这个大的 RNN 单元的输出则只有原先的最上层 RNN 的输出,即整体的
接口(对LSTM的封装)要具有良好的扩展性(水平扩展-sequence,垂直扩展-stack)。
在stack lstm中,下一层的out对接上一层的input,在深度模型的概念里这就是隐含层hidden的作用,所以命名为hidden。
但是呢,作为一个cell,我还是觉得叫output比较好。追根溯源,谁第一个采用hidden命名的?
为什么lstm代码里要把(c, h)封装成一个tuple?
- 为什么不拼成一个tensor?
- 为什么不用2个独立元素?
这样设计的目的是为了兼容RNN的接口(毕竟LSTM属于RNN的一种)。另外
- pytorch 源码 - LSTM
- tensorflow源码 - BasicLSTMCell
example 应用示例
应用示例–基于lstm的语言模型
1 | lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size) |
LSTM: 实现
In order to make the learning process tractable, it is common practice to create an “unrolled” version of the network, which contains a fixed number (num_steps) of LSTM inputs and outputs. The model is then trained on this finite approximation of the RNN. This can be implemented by feeding inputs of length num_steps at a time and performing a backward pass after each such input block.
为什么要有限长度?
对于任意长度的序列,BP算法计算复杂,因此采用固定长度的序列。
为什么要固定一个静态长度?
是tensorflow的静态图从中作梗吧,动态图则没有这个限制。
LSTM: tensorflow实现
tensorflow源码 - BasicLSTMCell
1 | # 源码精简版 |
pytorch
包装的好复杂,参考 https://blog.ddlee.cn/2017/05/29/LSTM-Pytorch%E5%AE%9E%E7%8E%B0/
缺陷
- 难并行
- 计算量大
- low rank approximation之类的参数控制,运算量会是对应RNN的四倍以上。所以Gating其实是一种代价很高的方法。
- 难优化
FAQ 汇总
关于静态图和动态图?
- LSTM为什么要设置cell? cell state 和 hidden state的关系、区别?为什么lstm代码里和有些图里,习惯吧output称作h(hidden)?
- 为什么要引入gate?
- gate是点,还是向量?
- 向量, decides what parts of the cell state we’re going to output
- LSTM为什么不用ReLU?
其他参考
- Understanding LSTM Networks | colah
- Recurrent Neural Network Regularization | tensorflow中BasicLSTMCell对应的paper
- Supervised Sequence Labelling with Recurrent Neural Networks
- Understanding, Deriving and Extending the LSTM | R2RT
- Revisit Long Short-Term Memory: An Optimization Perspective | 朱军大佬
- 地平线语音战略与研究
其他
黄畅:我补充一点。关于 LSTM,不管你是单向的、双向的、摞一起的、不摞一起的,其实都有一个问题:信息传导的约束很强。换句话说,不管是做前向预测还是后向 BP(反向传播),一个信息从左边到右边,或者从开始到结束,都要经过很长的路径。而且在整个过程中,会有很多非线性的变化,尤其是 LSTM 这种典型的、很容易进入自我限制状态的模型。经过很多次这样的事情,就导致整个优化变得异常困难。这个结构天生就使得优化变得非常困难。
xusong: 加上skip connection呢,这个可以加在LSTM内部,也可以外部
这是 LSTM 的弊病,它的结构设计有很大限制性。你可以类比一些其他结构,比如 ResNet,它通过建立 free-way 的方式,人为地架了很多 short-pass(短路径),使得本来在网络上距离很远的两个单元之间建立一些高速的快速通道。直观的理解就是可以让它们之间的信息沟通更加顺畅,减轻我前面说的那个问题。
更进一步,你会发现在语音识别中有人用完整的 CNN 替代 LSTM,包括讯飞、微软、百度。刚开始的时候 CNN 用得很浅,只是作为基本的局部表达,后来发现可以用 CNN 不断堆积,而且堆的很有技巧。在计算量不显著增加的情况下,这样就可以用 CNN 覆盖很大的语境。
就是说优化算法本身也许没有很好的进步,但是通过网络结构的设计可以规避目前主要基于 SGD 的优化算法难以解决的 LSTM 问题,直接构造一个更适合目前优化算法去优化的网络结构。所以本质上很难说哪个结构更好,你只能说这个结构更适合现在主流的这种优化方法。
其实论文出来时我稍微看了一点,它本质上好像和 attention model 很像。attention model 的概念是不管语境是怎么传过来的,总是有选择的看所有东西,做决策(比如生成一个词)的时候有选择的去做。这时候会产生一个 attention mask,这可以理解成一个 gate,封住一些不想看的东西,保留想看的。
这个在图像和 NLP 里面已经得到很好的验证。NLP、语音、图像其实都是相通的,你会发现很多思想、结构、设计理念会越来越相似。这也给了我们信心,让我们可以实现语音图像识别一体化交互,用一套统一的专用架构去做解决各种各样的问题。