update: Estimator已经独立出tensorflow成为了一个独立的项目
背景
通常的tensorflow编程流程是
- 构造
graph,并得到loss节点 - 构造
optimizer - Session.run(graph, feed_dict)
举个例子
1 |
流程简洁、清晰。但是…
Estimator是对以上流程的封装。
- 对graph拆分,
- 对session.run进行包装
- optimizer呢?
- feeddict呢?用dataset
Estimator优势
Estimator 具有下列优势:
- 您可以在本地主机上或分布式多服务器环境中运行基于 Estimator 的模型,而无需更改模型。此外,您可以在 CPU、GPU 或 TPU 上运行基于 Estimator 的模型,而无需重新编码模型。
- Estimator 简化了在模型开发者之间共享实现的过程。
- 您可以使用高级直观代码开发先进的模型。简言之,采用 Estimator 创建模型通常比采用低阶 TensorFlow API 更简单。
- Estimator 本身在 tf.layers 之上构建而成(https://tensorflow.google.cn/api_docs/python/tf/layers?hl=zh-CN),可以简化自定义过程。
- Estimator 会为您构建图。
- Estimator 提供安全的分布式训练循环,可以控制如何以及何时:
- 构建图
- 初始化变量
- 开始排队
- 处理异常
- 创建检查点文件并从故障中恢复
- 保存 TensorBoard 的摘要
使用 Estimator 编写应用时,您必须将数据输入管道从模型中分离出来。这种分离简化了不同数据集的实验流程。
汇总
- 定义model_fn,并实例化Estimator
- 定义input_fn
- train_data、train_step
- eval_data、eval_step
另外还可借助Hparams的封装传参
Estimator
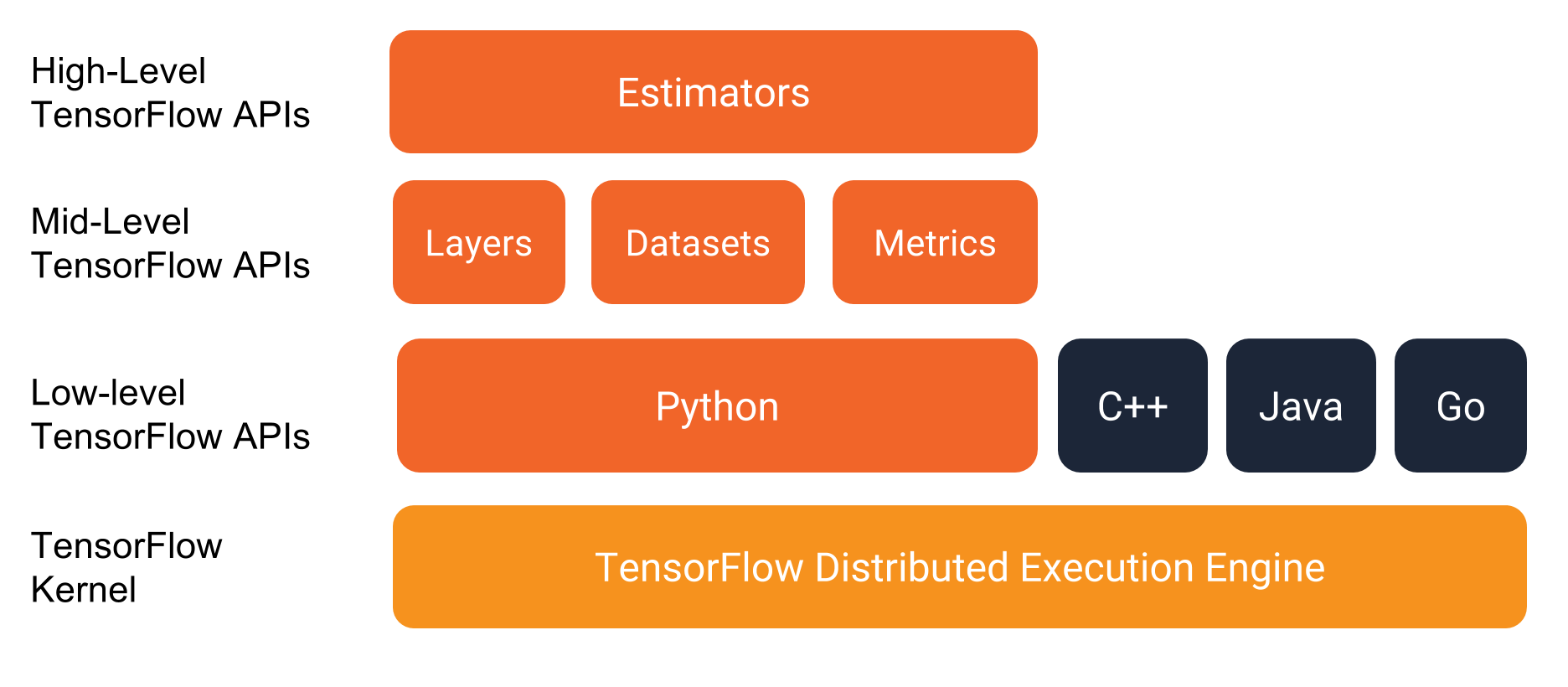
tf.estimator是TensorFlow的高层API,是对底层API对以下方法进行了封装。
- training: 对应 ModeKeys.TRAIN
- evaluation: ModeKeys.EVAL
- predict: ModeKeys.PREDICT
- export for serving
用法
有两种使用方式,都需要依赖tf.estimator.Estimator这个类。
预创建的 Estimator
基于Estimator,官方预定义了一些常用的模型,比如DNNClassifier、DNNRegressor、LinearClassifier、BoostedTreesClassifier等。
以下是一个完整实例: 利用DNNClassifier对花萼分类,其核心代码就几行,充分展现了Estimator封装的简洁性
1 | classifier = tf.estimator.DNNClassifier(features, labels, hidden_units, n_classes) # 实例化estimator |
官方这几个model也为我们使用Estimator提供了例子
自定义 Estimator
官方定义的模型不能够满足我们的需求,那就需要基于Estimator自定义模型
无论是pre-made,还是custom,其核心都是model function。
在该方法中需要构建graph,包含training, evaluation, and prediction。
具体实现
Estimator的封装,基本思想是让我们只需关心模型和数据,屏蔽硬件(是吗?)。
要实现这种封装,一种思路是抽象类(接口) + 继承 + 覆盖,另一种是完整类 + 传函数。Estimator显然更钟情于第二种方式(why?)。
- model_fn 定义模型,即构建graph,主要要包含TRAIN、EVAL、PREDICT对应的op。
自己定义model_fn
model_fn传给Estimator
model_fn必须要以Estimator构造函数的方式传递。
pre-made
DNNClassifier的实现
1 | class DNNClassifier(estimator.Estimator): # 定义Estimator的封装,没必要 |
这仅仅是对Estimator的一个封装,对外直接用DNNClassifier而无视Estimator的存在。
自己的程序,没必要这样封装,屏蔽掉Estimator而定义一个新类,会让其他程序员看的摸不着头脑。
不建议采用继承的方式,还是开放Estimator比较好吧,即后面的custom方式
custom
优势
- Estimator对底层隔离,兼容CPU、GPU、TPU、多卡、多机多卡 666
- 其他几个优点没看懂
Estimator
estimator与keras的关系,
Datasets for Estimators - input_fn
注意,上面定义的model_fn并非完整graph,因为其中并未构造input节点,而是input作为参数。
因此我们要定义input_fn,并构造input节点。然后传入model_fn,从而构造完整graph。
给Estimator传入数据,通常为train何eval分别定义一个input_fn函数,该函数有三个参数:
- features:字典或DataFrame类型,包含输入数据的特征,与Feature Columns对应
- labels:标签数组
- batch_size:batch size
1 | dataset = dataset.shuffle(1000).repeat().batch(batch_size) |
- repeat 要迭代数据集多个周期,例如,要创建一个将其输入重复 10 个周期的数据集repeat(10),无参表示无限次地重复输入。
- shuffle 随机重排输入数据,维持一个固定大小的缓冲区,并从该缓冲区统一地随机选择下一个元素。
- batch 每次取多少个数据
TrainSpec、EvalSpec
TrainSpec是对以下的封装
input_fn:max_steps:hooks:
其他
run_config
tf.estimator.RunConfig
原
tf.training.HParams
原tf.contrib.training.HParams
1 | def __init__(self, |
run_config VS hparams
run_config 是个模板,session run需要用到的参数。
hparams是
吐槽环节
tensorflow跑一个程序,有n种方式。看了后想骂人。
传统方式
1 | # Custom training |
tensorflow keras
1 | # tensorflow keras |
FAQ
- stimator节省了哪些操作?
- 与硬件底层的隔离,免去了写多机多卡的code。源码
- estimator能否与low-level API交叉使用?
- Estimator中怎样打log?
- Estimator封装了很多logging.info,一般不允许自己插入其他log吧
- Estimator如何做多卡?多机并行?如何分配worker和ps?怎样的并行策略? 源码
- Estimator屏蔽硬件吗?在model定义时是否可以设置device?
扩展阅读
- https://www.tensorflow.org/guide/premade_estimators
- Estimator介绍 | Tensorflow微信公众号
- Estimator源码
- 实例:
- pre-made estimator实例
- custom estimator实例